
About a month ago, my friend and colleague Siebe introduced me to a document called the Customer Experience Digital Data Layer standard, or CEDDL for short. It’s a standard for data layers that describes how onsite data can be structured in a JavaScript object. It was created at the end of 2013 as a uniform way to define a website’s data layer.
The CEDDL structure
The CEDDL standard is a not an official standard. This means that you don’t need to use it, but could use it as a guide. Here’s a data layer sample for page variables based on this standard:
digitalData = {
pageInstanceID: "MyHomePage-Production",
page:{
pageInfo: {
pageID: "Home Page",
destinationURL: "http://mysite.com/index.html"},
category:{
primaryCategory: "FAQ Pages",
subCategory1: "ProductInfo",
pageType: "FAQ"},
attributes:{
country: "US",
language: "en-US"}
}
};
As you can see, it’s basically one JavaScript object with nested variables. The same structure is used for other information such as basket or transaction data. It’s interesting to note that a lot of companies were involved when the standard was created. Here’s a list of some of them:
- Adobe
- Best Buy
- BrightTag
- Criteo
- Ensighten
- IBM
- LunaMetrics
- Qubit
- Snowplow Analytics
- Tealium
This made us wonder: do the data layer standards of the tag management vendors in this list match the CEDDL standard?
Put the money where your mouth is
To find out, I reached out to the tag management vendor we directly, or indirectly work with at Blue Mango. The list of vendors we currently work with contains three companies from the list:
- Qubit – Qubit Opentag
- Google – Google Tag Manager
- Tealium
And one that’s not in the list:
- Relay 42
We’ve noticed that all of the data layer standards are different from the CEDDL standard. So when I contacted the vendors, I asked:
Why does the [tag manager] data layer differ from the CEDDL standard?
Let’s look at the replies.
Qubit
Contact: Harry Hurst – Director, Partnerships at Qubit
Data layer standard: Universal Variable
The data layer
The Qubit data layer, the Universal Variable, is a nested JavaScript object. Here’s an example of the page variable from their docs:
universal_variable = {
"page": {
"type": "content",
"breadcrumb": [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]
}
}
The nested structure is easy to read. The page variable contains all page related variables. The page type variable contains information about the type of the page. Therefore, it’s nested inside the page variable. You can use the variable with universal_variable.page.type. This makes the object similar to the CEDDL structure.
Why does the Qubit data layer differ from the CEDDL standard?
The W3C data layer is based on a collaboration of lots of online businesses including Qubit. In fact, Qubit’s UV model was submitted as an original template for what this became – we had our model running live with clients several years before the CEDDL standard was agreed and have continued with our naming structure to meet the specific needs of our clients.
We can work with the CEDDL or other any suitable, pre-existing data layer but always push for best practice adoption of values that reflect the desired output of the marketing technology that will use it. So for example, having a data layer which provides values designed for adtech will probably not meet the needs of a personalisation technology. The reality is that our understanding of what data clients require moves faster than the standard can adapt so we’ll always be slightly ahead of this kind of template. In each case, we believe that the client should be able to define the values which are important to their business, without limits and then be able to use that full breadth of data.
Harry mentions that Qubit has been working with a data layer long before the standard was set. Because of this clients had their data layer installed already. Besides that, the original plan was to use the UV as a standard (see their GitHub page updated in January 2013). These were the two main reasons why Qubit decided not to change it. Another good point is that development of data layer requests by clients (or custom changes to the Universal Variable by Qubit) move faster than the adaption of these same requests by a standard. So custom versions of a data layer will always be ahead of the standard.
Google Tag Manager
Contact: Lukas Bergstrom – Product manager for Google Tag Manager
Data layer standard: dataLayer
The data layer
Google data layer setup, the dataLayer, is not a single object, but an array containing objects. Let’s look at a page example:
dataLayer = [
{
"page": {
"type": "content",
"breadcrumb": [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]
}
]
If you’d want to get the pagetype in this structure, it’ll be less easy to do it with vanilla JavaScript. You’ll basically have to loop through your objects to find the page variable:
for (var i = 0; i < dataLayer.length; i++) {
if(typeof dataLayer[i].page !== 'undefined'){
console.log(dataLayer[i].page.type);
}
}
As soon as you’re logged into GTM, and enable the preview mode, things get a lot easier. The preview mode shows you a clear overview of the data layer. Inside GTM you can get the variable more easily by simply setting up a data layer variable (page.type):
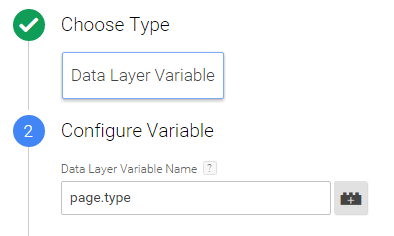
Sample page type variable setup Google Tag Manager
Technically, this makes for quite a different data layer setup than the CEDDL standard. An extra reason to find out why Google took this approach.
Why does the GTM data layer differ from the CEDDL standard?
The issue is when you have different bits of code on the page that might need to update the CEDDL/data layer. The data layer will avoid any race conditions – different parts of the page can push data and events to its queue of messages and it will just process them in order. The CEDDL, as a static data object, could be changed by one event handler before a prior event handler has been able to send the data it just updated the CEDDL with.
In other words, with Google data layer setup, you’ll be able to keep updating the data layer by pushing objects into it (messages). All of these messages will be handled separately. Making sure that e.g. ecommerce update one (e.g. a product view) won’t conflict a second update (e.g. a list of suggested product impressions). In one nested object, you could theoretically change the data layers variables while your changing it.
Tealium
Contact: Ali Behnam – Co-Founder, Tealium
Data Layer Standard: custom data layer
The data layer
The Tealium data layer is custom. They don’t have a specific default spec. Looking at their best practices, they describe two structures:
- Flat: a JavaScript object with one level
- Multi-level: a JavaScript object with nested variables (more closely related to the CEDDL)
Looking at two examples:
Flat structure example:
var flat_data = {
page_type : "content",
page_breadcrumb : [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]
}
Multi level structure exmample:
var multi_level_data = {
page : {
type : "content",
breadcrumb : [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]
}
}
As Ty Gavin describes on the Teailum blog, the first one is easier to use when coding. You can easily see if a variable is available. In the multi-level structure, you’ll have to check if all the levels are available (so page, page.attributes, and page.attributes.type).
Why does the Tealium data layer differ from the CEDDL standard?
Thanks for reaching out. You’re right that none of the TMS vendors or frankly none of the digital marketing vendors (i.e. analytics) have adopted the W3C standard as their own best practice. However, one thing to be optimistic about is that pretty much all vendors are now advocating the use of a single data object for implementation. In our case, we can read the W3C standards just fine, although it’s not our best practice for reasons below.
I can only speak for Tealium. Our data layer best practice is to have a single data layer and allow customers to define their data values in that single data object. By default, we name our data object utag_data, but the name can be changed to anything, so as an example the customer can change the name to digitalData (W3C naming) or dataLayer (Google naming) and it will all work. So we treat the name as exactly that: a name.
Another area where you will see differences between us and W3C is in naming of the variables. Our position again is that these are just names. Our best practice is to allow customers to define whatever data they want in as easy a process as possible. Take for example product name, in W3C you’ll have to adhere to a specific name and hierarchy, but in our case you call it anything (i.e. product, product_name, productName, sku, or produkt – if the customer is German speaking and prefers German names).
So to summarize, the primary reason for our best practice has been to make life easier for customers. We strongly feel that the TMS product should be able to accommodate customer preference, and not vice-versa.
What I most like about Ali’s reply is last line: the client should be leading and the data layer should be defined by their wishes. I also like how his story matches that of the blogpost by Tealium I mentioned: data layers can be flat and simple, or complex and multi leveled. There are scenario’s for either one.
Relay 42
Contact: Yorick Breuker – Support Engineer at Relay42
Data Layer Standard: _st (no public docs)
The data layer
What makes the Relay 42 data layer unique is that they offer both a synchronous and asynchronous data layer capture. You’ll pass the following information when adding a property to the data layer:
- property label: what property are you pushing?
- property value: what value does the property have?
These data layer changes can handle all types of data: integers, strings, objects, etc. Here’s are some code examples for possible page variables, both simple, more complex, synchronous and asynchrounous:
Async single properties example:
_st('addTagProperty', 'page_type', 'content');
_st('addTagProperty', 'page_breadcrumb', [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]);
Async object property example:
_st('addTagProperties', {
type : 'content',
breadcrumb : [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]
});
Sync object property example:
_st.data.setProperty('page',{
type : 'content',
breadcrumb : [
"The Fashion Blog",
"London Fashion Week '13",
"Behind the scenes at the River Island fashion show"
]});
Technically, the support for both a sync and async data layer additions is unique. Relay sends properties separately to the data layer. This makes it more like Googles dataLayer specification than the CEDDL, where you define a simple JavaScript object.
If you want to access the data directly with JavaScript, you can do so with the following function.
_st.data.getProperty('naam');
Keep in mind that Relay42 has easier ways to view available data with their tag management system. For example the function _st.debug.enable(), this will show you the available parameters on the current page.
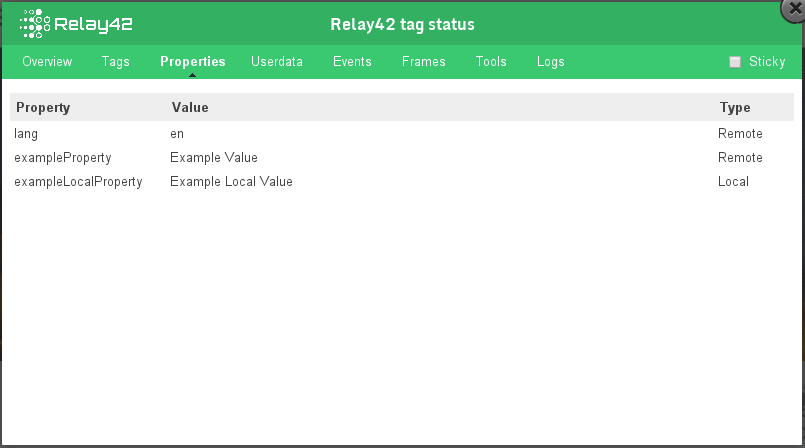
Sample popup from the Relay42 tag manager showing available variables of the current page.
Why does the Relay42 data layer differ from the CEDDL standard?
To give you a straight answer; The Relay42 philosophy desires more flexibility, and the best practices were already developed before the CEDDL standard was. This doesn’t mean you can’t use the CEDDL standard for your Relay42 implementation though.Relay42’s approach is similar to Google’s, pushing separate updates to a queue and handling them all independently.
A datalayer is mainly semantic. It is referring to the place in/on the website where you can find all relevant information. Although we fully support the ideology of a global standard, the way in which this should be done is a trivial discussion. In our case, we have few nice features in place, which wouldn’t be possible when using a ‘vanilla’ javascript object like stated in the CEDDL standard. There are a few things though, we consider important in a datalayer:
- Being flexible and client centric. Although the Relay42 basescript mostly remains the same, we still host a seperate basescript for each of our clients. The reason for this is that we want to offer our clients the possibility to let us customize it, to make it refer to an alternative custom datalayer for example.
- Usability: We want our users to be able to use available data without any technical knowledge. To achieve this, we offer all kinds of templates for third party vendors, in which our interface integrated the datalayer, and provides you with a list of available properties for the page you want to place a tag on. You can select these properties for tracking just by clicking them.
- Correct handling of privacy sensitive information. The examples of adding data to the Relay42 datalayer, can be extended with the ‘local’ prefix. When doing so, you explicitly deny the property from being available for tag management server logic. This allows you to be privacy compliant in every situation.
A technically correct solution for every implementation. As you can see in the examples given, there is a synchronous and an asynchronous way of handling commands. This way our clients can be sure that performance issues won’t be a problem.
What sets Relay42 apart from Google (the most similar when comparing the data layer setup) is that their tag manager automatically show available variables in their tag manager. This way, non-technical people instantly get a list of available variables on a page they want to place a tag on. Quite convenient. The other tag managers require you to manually add the variables to the tag management system.
The lesson learned
The data layer is something that’s very client dependent. Just as each company has its own structure, so should the data layer. I like the way Ali from Tealium looks to it:
The technical specification should never be leading, the client should be.
Technically, Qubit sticks closest to the standard by clearly opting for a nested data layer in the documentations. Though Tealium is close, allowing for various data layer setups. Besides that, it’s good to know that they all support custom object in one way or another:
- Tealium: set a custom data layer object.
- Qubit and Relay42: write a data layer wrapper.
- All: use custom JavaScript tags to read and handle the data layer on your site.
Our view on the data layer
At Blue Mango, we’ve been working with tag managers and data layers since mid-2012. Over the past years, we’ve learned the value of a well defined data layer and because of this, our briefings have changed. We currently define two parts in our data layer implementation documents:
1: The general part
For the general part, we take a tag managers standard documentation, and apply it to our client’s website. In this part, we remove all data that’s unnecessary. We also try to learn from one tag managers data layer standards, and apply it to others. For example: Qubit’s Universal Variable standard contains more information that Google’s. Two useful variables from Qubit are:
- User variable: containing information about the user, for example their user ID or a Boolean that tells us if a user has transacted before.
- Page variable: containing information about the page, for example the virtual url path, a breadcrumb array and page types.
We’ve noticed that some standards are really useful. Page type is one of them. If you want to learn how to apply this standard to GTM, read my article about it here.
2: The client specific part
The second part contains client specific information. This contains information that isn’t generally applicable. Think about the duration of a phone contract, or a the fuel type of car. We put these in a separate chapter as additions to the standard data layer.
Structure
Personally, I like the single object approach because it has a readable structure. This makes the data layer open, allowing developers and web analyst to explore the object easily. Other data layer structures have options to view the more complex data layer more easily, but they always require you to either login or install an extra plugin. In other words: one extra step.
It’s about what the data layer can do for the client
What it comes down to is that you should always put your client first. That way, you’ll optimize the power of the data layer for the client. Keep in mind that theoretically, you can use each data layer with each tag manager. So if you see a great post about best practices for Qubit Opentag, GTM, Tealium or Relay42 and it’s not about the tag manager you’re using, try to look for a way to implement it in your system of choice.
A final note
We use Qubit Opentag’s Universal Variable data layer standard with Google Tag Manager on The Marketing Technologist. It works like a charm.




Leave a Reply
You must be logged in to post a comment.